
Designing Data-Intensive Applications in 2026: An Architectural Retrospective
A definitive review of Martin Kleppmann's foundational text, updating its distributed systems theory for the modern era of NVMe storage, unified lakehouses, and orchestrated sagas.


Martin Kleppmann’s Designing Data-Intensive Applications is basically required reading for backend engineering. The core premise still holds up: data volume, complexity, and velocity constrain architecture far more than raw CPU cycles.
But hardware doesn’t stand still. Reading the book in 2026 requires updating the physical variables Kleppmann used in his assumptions. When you swap in modern NVMe storage and unified compute engines, the structural trade-offs he outlines shift significantly. Here is a look at what actually survives contact with modern production infrastructure.
1. Storage: The Metal Layer
Kleppmann dedicates a lot of space to the trade-offs between the traditional B-Tree and the Log-Structured Merge-tree (LSM-tree).
The B-Tree updates fixed-size logical disk pages in-place. DDIA correctly points out why this was a problem on magnetic hard disk drives (HDDs). Modifying a small record meant reading an entire page into memory, updating it, and writing it back to random locations. Because HDDs rely on mechanical arms, random seeks killed your IOPS.
LSM-trees bypassed this by turning random writes into sequential logs. Data is appended to a Write-Ahead Log and a memory buffer, then flushed to disk as immutable Sorted String Tables. It solved the HDD write bottleneck but introduced the compaction tax. Background compaction burns CPU and saturates disk I/O, which causes unpredictable tail latency spikes.
The 2026 Reality: The modern data center runs on enterprise NVMe SSDs. These drives use highly parallel flash channels that largely neutralize the performance gap between sequential and random writes.
More importantly, modern enterprise SSDs have internal hardware controllers that perform transparent compression directly on the physical I/O path. If you use a modern B-Tree variant that logs zero-padded delta updates, the NVMe hardware instantly compresses the zeroes away. This drops the write amplification of the B-Tree from over 200x down to roughly 20x.
For general-purpose workloads today, the B-Tree is usually the better default. You get predictable read performance without paying the LSM compaction tax, because the hardware solved the random-write problem for you.
2. Distributed Data: The Network Layer
When dealing with distributed transactions, DDIA covers coordination protocols like Two-Phase Commit (2PC). In 2PC, a coordinator asks all participating nodes to place pessimistic locks on database resources before committing.
While the book acknowledges the performance hit of 2PC, its blocking nature is a complete non-starter in modern async architectures.
The 2026 Reality: Today’s infrastructure relies heavily on long-running AI workflows and agent swarms. A single workflow might take hours to resolve. You cannot hold synchronous database locks across a distributed cluster for hours without causing complete system gridlock.
The industry has largely abandoned strong global consistency in favor of eventual consistency. We rely on Orchestrated Sagas and the transactional outbox pattern. You isolate the transaction locally, commit it, and publish an event to trigger the next step. There are no distributed locks held across service boundaries.
3. Derived Data: The Unbundling Layer
One of the best concepts in DDIA is unbundling the database. Instead of treating a single RDBMS as the system of record and fighting to keep caches in sync, you treat an append-only event log (like Kafka) as the source of truth. The database and search indexes are just materialized views derived from that log.
To handle analytical workloads in this model, DDIA discusses the Lambda Architecture. This involves maintaining a slow batch pipeline for accuracy and a fast stream pipeline for real-time approximation.
The 2026 Reality: In practice, Lambda was an operational nightmare. You had to write, debug, and maintain your business logic twice across two different frameworks. That pattern is dead.
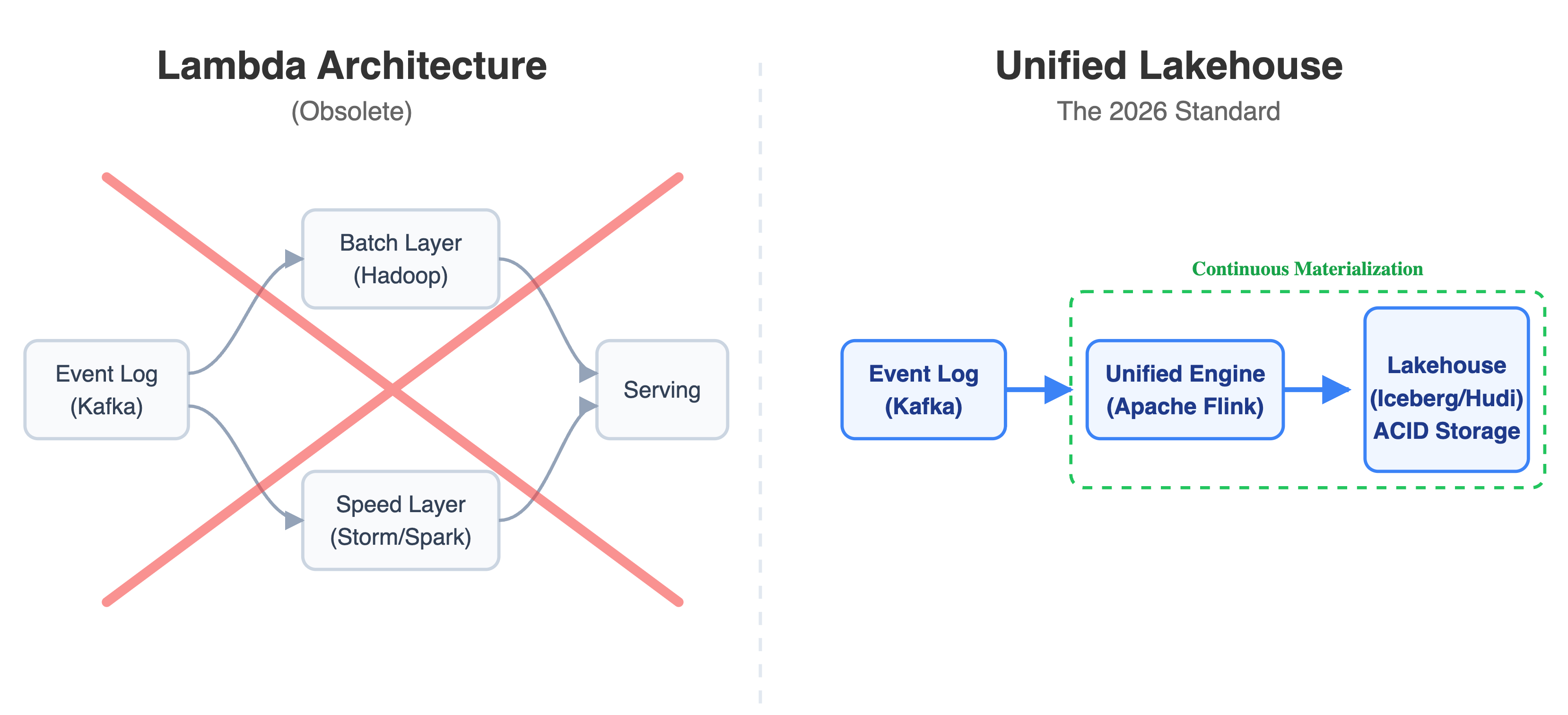
The maturation of unified execution models like Apache Flink operating over Lakehouse formats like Apache Iceberg has eliminated the need for it. “Batch” is now just treated as a bounded stream operating over a finite dataset. You get ACID transaction guarantees directly on top of scalable object storage. You write the pipeline once, and it handles both real-time ingestion and historical batch queries using snapshot isolation.
Final Thoughts
DDIA is still the best baseline we have for distributed systems theory. The abstractions are correct. But as engineers, we can’t treat the implementation details as dogma. The physical hardware dictates the architecture. Update the hardware assumptions, and the correct architecture changes with it.